


This article will cover the implementation of a for loop with multiprocessing and a for loop with multithreading. We will also make multiple requests and compare the speed.
Table of Contents
- Sequential
- MultiProcessing
- MultiThreading
- Sharing Dictionary using Manager
- ‘Sharing’ Dictionary by combining Dictionaries at the end
- Comparing Performance of MultiProcessing, MultiThreading(making API requests)
I have written all the code in google colab, you can access the notebook here
Sequential
We will be making Post requests to this API. The function post_req has a parameter called data. This parameter will contain the data which will be sent to the API
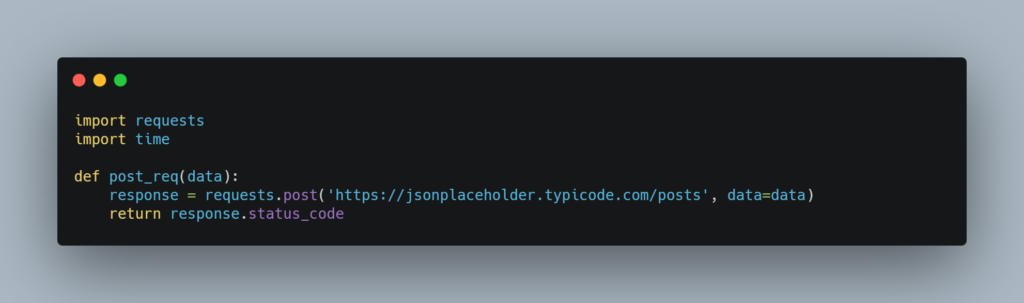
Below is the Sequential way of making 500 Post requests to the API.
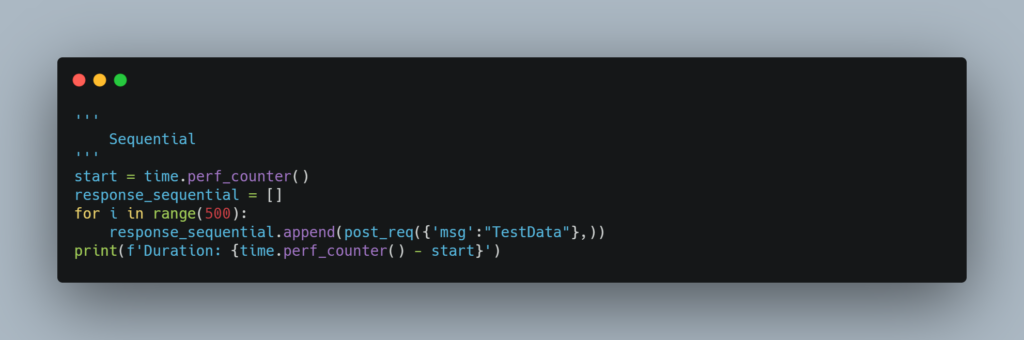
On google colab, this piece of code took around 100 seconds to complete.
Multiprocessing
We will be making 500 requests to the above-mentioned API. We will be using the concurrent package. Below is the general format to use multiprocessing for a for loop
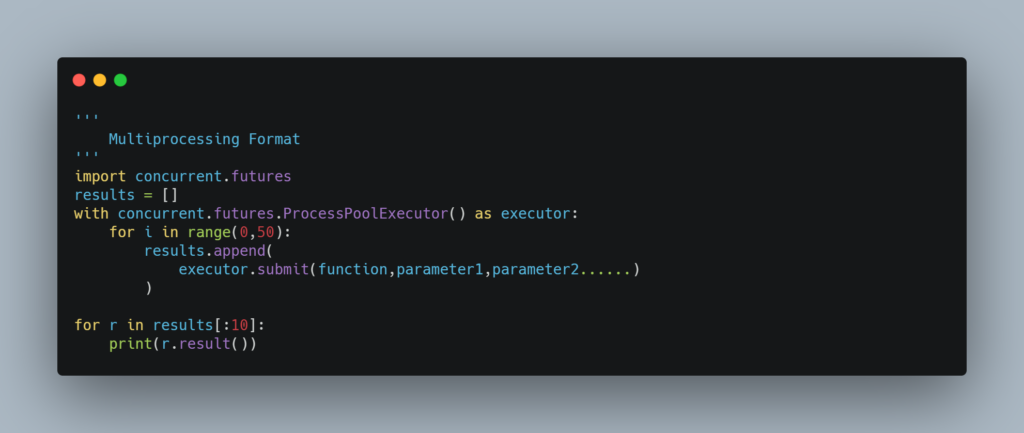
concurrent.futures.ProcessPoolExecutor allows you to set the maximum number of proccesses to be used by setting a value for the max_workers parameter
The function parameter of executor.submit() should not have any brackets since we do not want to invoke the function.
submit() returns a future object. To get the actual returned value of the function, we will use the result method of the future object. The returned values can be in any order.
Below is how we would use multiprocessing to make the 500 requests
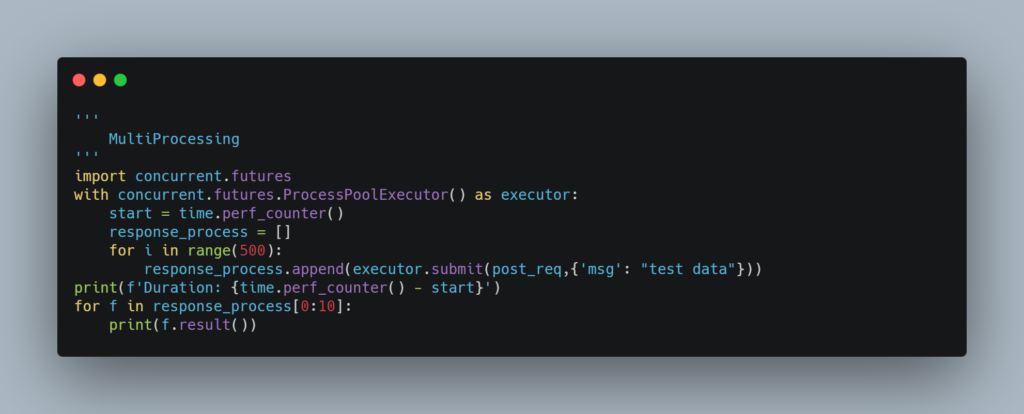
In google colab, this took around 50 seconds. If your piece of code executes in less than a second, there is probably an error somewhere. To check the error during multiprocessing, simply print the result of one of the future values.
Multithreading
The format for multithreading is pretty similar to multiprocessing. The only difference is instead of concurrent.furtures.ProcessPollExecutor(), we will use concurrent.futures.ThreadPoolExecutor()
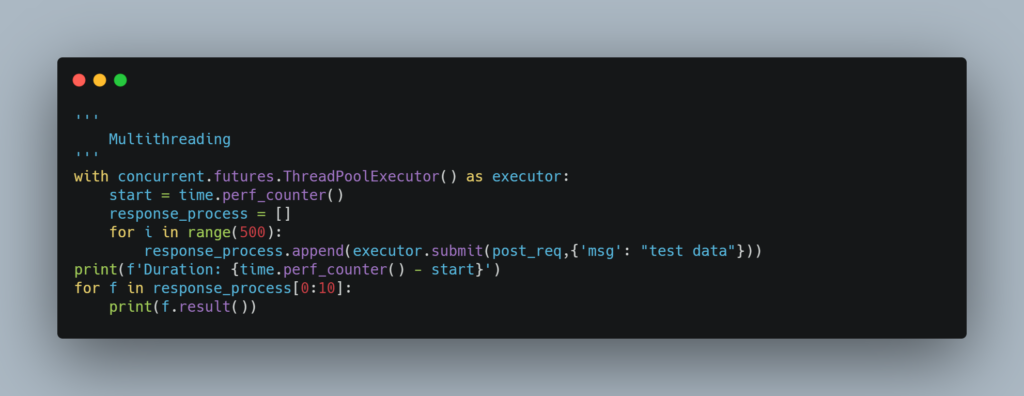
Above is the piece of code which makes 500 requests using Multithreading. In google colab it took around 15 seconds. To check the error during multithreading, simply print the result of one of the future values.
concurrent.futures.ThreadPoolExecutor allows you to set the maximum number of threads to be used by setting a value for the max_workers parameter
Sharing Dictionary using Manager
We are going to use a dictionary to store the return values of the function. The key will be the request number and the value will be the response status. Since we are making 500 requests, there will be 500 key-value pairs in our dictionary.
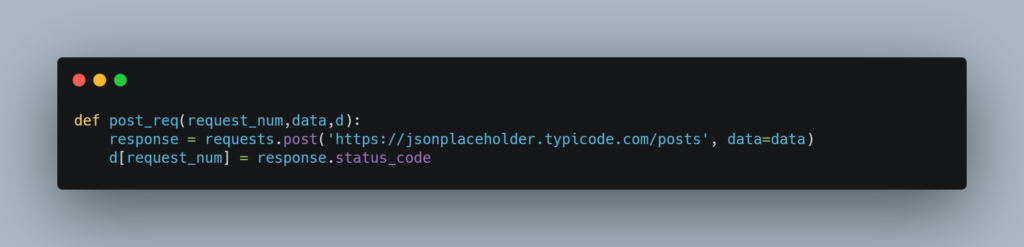
The parameter d is the dictionary that will have to be shared.
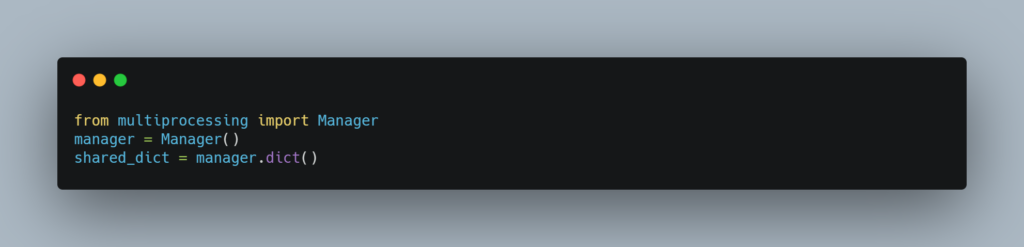
To share a dictionary we will use Manager().
Since the function is not returning anything, we do not need to store the future objects returned by the submit function.
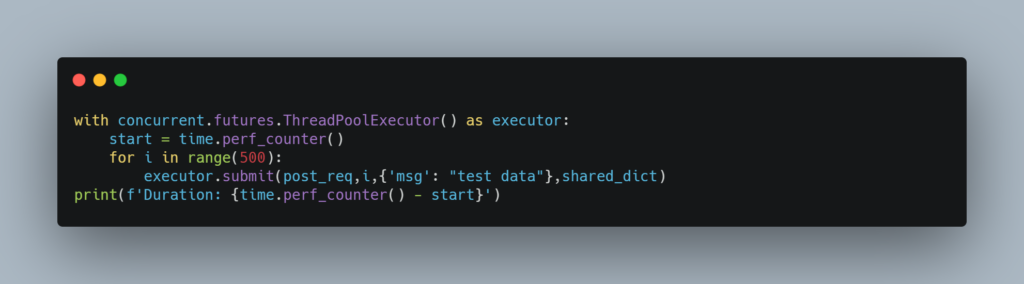
The dictionary created using Manager() is thread-safe and has a lock. This might make your program slow if there are a bunch of inserts.
‘Sharing’ Dictionary by combining Dictionaries at the end
We will need to update our function to return a key-value pair instead of directly storing it inside our shared dictionary
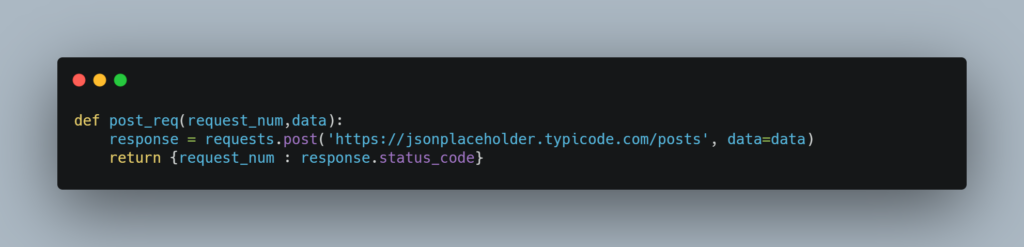
We will use a dictionary’s update function to store all the returned values. Below is the piece of code which invokes the function multiple times
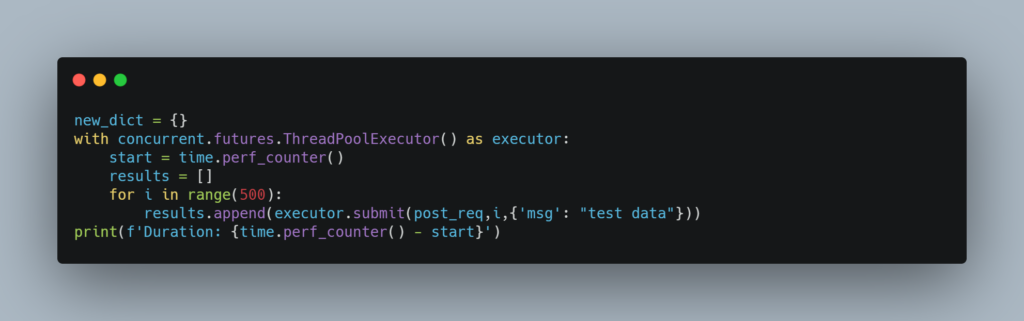
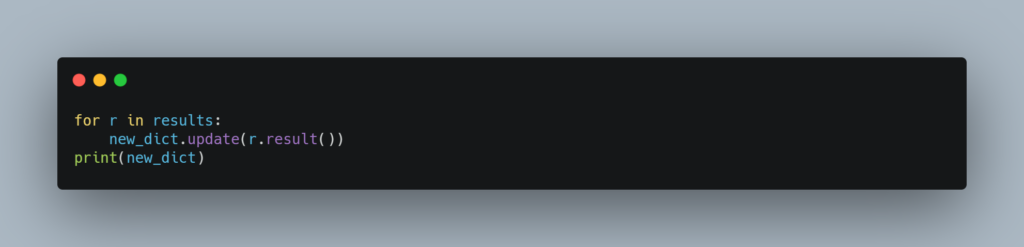
As you can see, this time we are storing the future objects since we will need them to store the returned values. We will essentially iterate over the list of future objects and update our dictionary
Comparing Performance of MultiProcessing, MultiThreading
We won’t be comparing with sequential code since sequential code is pretty slow and will take a long time to make a large number of requests.
We will be making 5 , 10 , 50, 100, 500, 1000, 2500, 5000 and 10000 requests.
To make it easier, we will create two functions. One of the functions would use multi-processing while the other would use multi-threading.
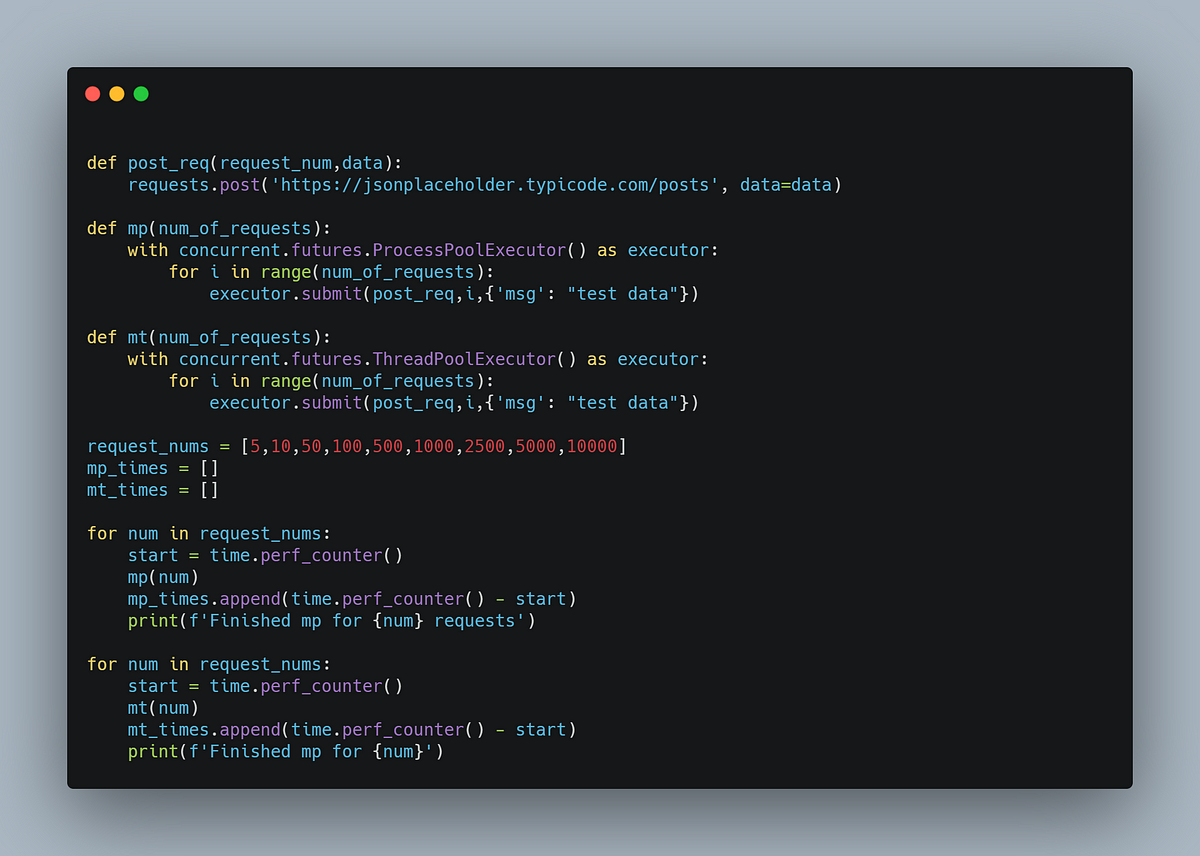 Code to compare
Code to compare
We will use the above times to plot a line graph to compare the performance
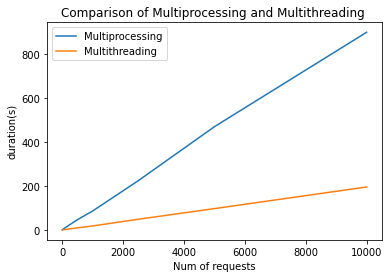
As you can see from the above graph, Multithreading performs better but this is because we are currently executing I/O functions(making requests to an API). When executing CPU-heavy functions (a lot of calculations), multiprocessing will be faster.
You can refer to the below article to see comparisons b/w Multiprocessing and Multithreading when dealing with CPU-heavy functions. The article also compares the performance with different values for max_workers