How to Build a Recommender System with Embeddinghub

A common problem in applied machine learning is how to recommend items in a database to users based on their past behavior. Features like text or categories need to be converted into a numerical feature and then embedded so that they can be used by models.
Usually embeddings — dense numerical representations of real-world objects and relationships, expressed as a vector — are stored in database servers such as PostgreSQLEmbedding. However Embeddinghub makes it easier to store your embeddings and load them. You can get started with minimal setup, and it also makes your code look less verbose as compared to, say, building a KNN model using scikit-learn.
This article walks you through using Embeddinghub to build a content-based recommendation model to recommend anime to a viewer.
Common Methods for Recommendation Systems
Before we dive into the setup, let’s explore our options. There are a few commonly used paradigms when it comes to building a recommendation model:
- Popularity-based filtering. This is the most straightforward type of recommendation model. It recommends the top items based on what the general population likes. The Top 10 in Canada on Netflix is a good example of a popularity-based recommendation model. An obvious caveat is that not everyone will like the moves in Netflix’s Top 10 in Canada.
- Content-based filtering. This works under the assumption that if the user liked item X, they would also like other items similar to X. Models like this try to find similarities between items and group them together. The recommendation given is based on the user’s likes and dislikes. This is the model you’ll be building in this article.
- Collaborative-based filtering. This model recommends items based on the actions of other users who are similar to you. The assumption is that if user A and user B are similar, both of them will have similar interests. If User B moves to a new genre of a movie all of a sudden, the model assumes that user A would do the same and so will recommend movies with the new genre to user A.
- Hybrid filtering. This model combines content-based filtering and collaborative-based filtering.
Common use cases of these various recommendation systems include:
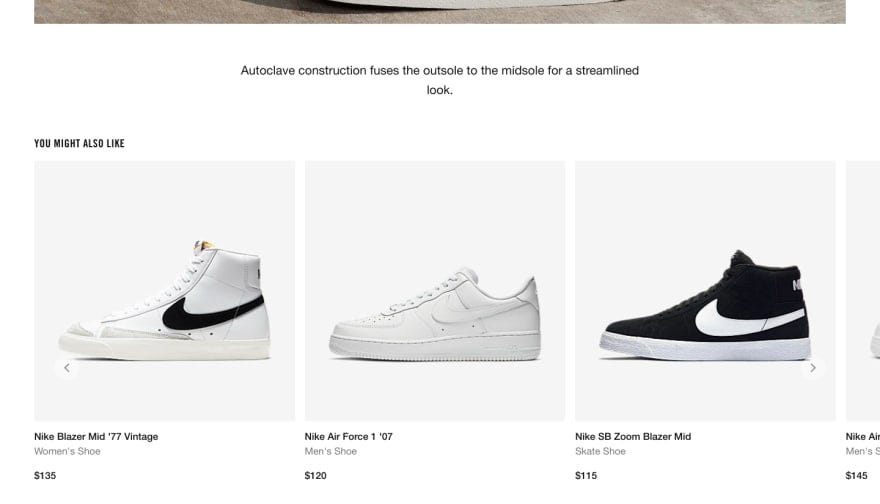
- Product recommendation. Most e-commerce stores have a section dedicated to recommending products to visitors. These are either based on the things a visitor bought earlier, the item they’re currently viewing, or their past browsing history.
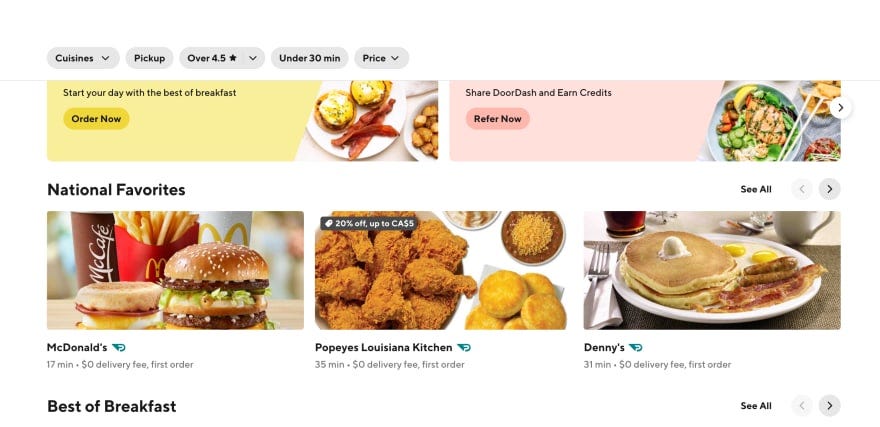
- Restaurant recommendation. Based on the previous restaurants a visitor has tried on apps like DoorDash and UberEats, they’ll get recommendations for new restaurants. They also recommend the most popular restaurants or national favorites.
- Media recommendation. Apps like Spotify, Netflix, and Youtube recommend media to you based on your browsing history. In fact, Netflix drives around 75 percent of its viewership due to its recommendation engine.
How to Build a Recommender System with Embeddinghub
For the purposes of this tutorial, you will be working with the anime recommendation dataset provided on Kaggle. You’ll use the data provided to build a content-based recommendation model. It will be able to recommend anime based on a show the user has watched. For example, if a viewer liked Pokemon, they might like Dragon Ball Z, Digimon, etc.
You’ll use Embeddinghub’s Python module to create a vector space (a space where you represent your feature’s embeddings. If your embeddings are two-dimensional, you will require a 2D vector space to represent them) and store your embeddings. You’ll also use Embeddinghub to recommend anime using a nearest-neighbor algorithm.
You can find the source code for this tutorial here.
Download Data and Setup Environment
Download the dataset here and create a new folder for the project.
mkdir anime-recommendationCreate a new virtual environment.
python3 -m venv venvAnd activate it.
source venv/bin/activateNext, install the dependencies.
pip3 install pandas embeddinghub protobufThere is a known issue in Embeddinghub about protobuf being a missing dependency. If you get a
module 'google' not founderror, you will need to install protobuf.
Load Data
You can download the anime data from here
Use pandas’s read_csv function to load the csv file as a dataframe. Print the dataframe to the console, then explore the columns.
For building the recommendation model in this tutorial, you will only need the genre of the anime. To keep it simple, you can use one-hot encoding to embed the genre.
Data Processing
As you might have noticed, the value in the genre column is basically a list of genres. You can use the following code snippet to embed the genres as one-hot-encoding
The dimension of your embedding is the total number of columns or genres. This will be required when you create the vector space. You can also add the anime_id and the anime's name to genre_df.
There is a known issue related to the maximum number of elements in an Embeddinghub vector space. For that reason, I only considered the first 2000 animes.
Create an Embeddinghub Vector Space
You’ll need to create a vector space to be able to represent your feature embeddings. In the previous section, you stored the number of genres. You’ll use this when you create the vector space.
In line 2, I used LocalConfig. However, if you wish, you can run Embeddinghub as a Docker container.
docker run featureformcom/embeddinghub -p 7462:7462Instead of LocalConfig, you could use the following:
hub = eh.connect(eh.Config())It basically defines where to store and index the embeddings. If you use LocalConfig, it will do so locally.
In line 3, a vector space with dimension equal to the number of genres is created. This is used to represent the embedding, i.e., the one-hot-encoding of your different anime.
Adding Embeddings to Vector Space
As mentioned at the beginning of this article, embeddings help represent real-world objects; in our case, anime are a vector with numerical values. These embeddings can help determine how similar two shows are.
Embeddinghub requires the embeddings to be in the form of a dictionary.
{key : value}In this case, value is the embedding, and key is something used to uniquely identify the embedding. The key could be the anime's name and the value could be the embedding.
Let’s create a dictionary with the anime and their respective embeddings.
You do not require the anime_id or the name for the value of the embedding. Therefore, the embedding will start from the third column.
Embeddinghub lets you write embeddings one at a time or in bulk. For convenience, we can write it in bulk.
Using Nearest Neighbor to Get an Anime Recommendation
Since you have a vector space with the anime’s embedding, you can measure the similarity of two anime by measuring the distance between them. The lesser the distance between them, the more similar they are.
Let’s try getting recommendations for a user who recently watched Kizumonogatari II: Nekketsu-hen. You can find its genres using the following code snippet:
Based on the genres, you would want the user to be recommended an anime along the same lines. To get recommendations, you can either use the key of the embedding (the anime’s name), or a vector (its embedding).
The num parameter is the number of recommendations or the number of closest neighbors you want. If you want to get a recommendation based on an embedding instead of the key, simply pass a parameter vector with the embedding instead of the key.
Areas for Improvement
A good recommendation model can always be made better. Here are a few key places where you might be able to improve your system:
- Reduce the number of dimensions of the vector space. The dimension right now is 82 since there are 83 genres. This might cause the nearest neighbor algorithm to suffer from the curse of dimensionality. In other words, items that are not similar will not be further apart from each other.
- Use a more sophisticated embedding algorithm with the help of a neural network, as opposed to one-hot-encoding.
- Make your embeddings more representative of the feature. The current embeddings ignore ratings and
anime_type(movie or TV show). Including these could improve the recommendations.
Conclusion
If you followed along with this tutorial, you just built a content-based recommendation model to recommend anime. And if you didn’t, the source code for it is right here.
Want to connect with the Author? 🤝
LinkedIn: https://www.linkedin.com/in/rahulbanerjee2699/
The article was originally posted on [realpythonproject.com](https://www.realpythonproject.com/how-to-build-an-anime-recommender-system-with-embeddinghub/)




