


In yesterday's article, we talked about getting started with Beautiful Soup. We discussed the following functions
- pretiffy()
- find()
- find_all()
- select()
Today we will try to scrape the data in the table of the worldometer website
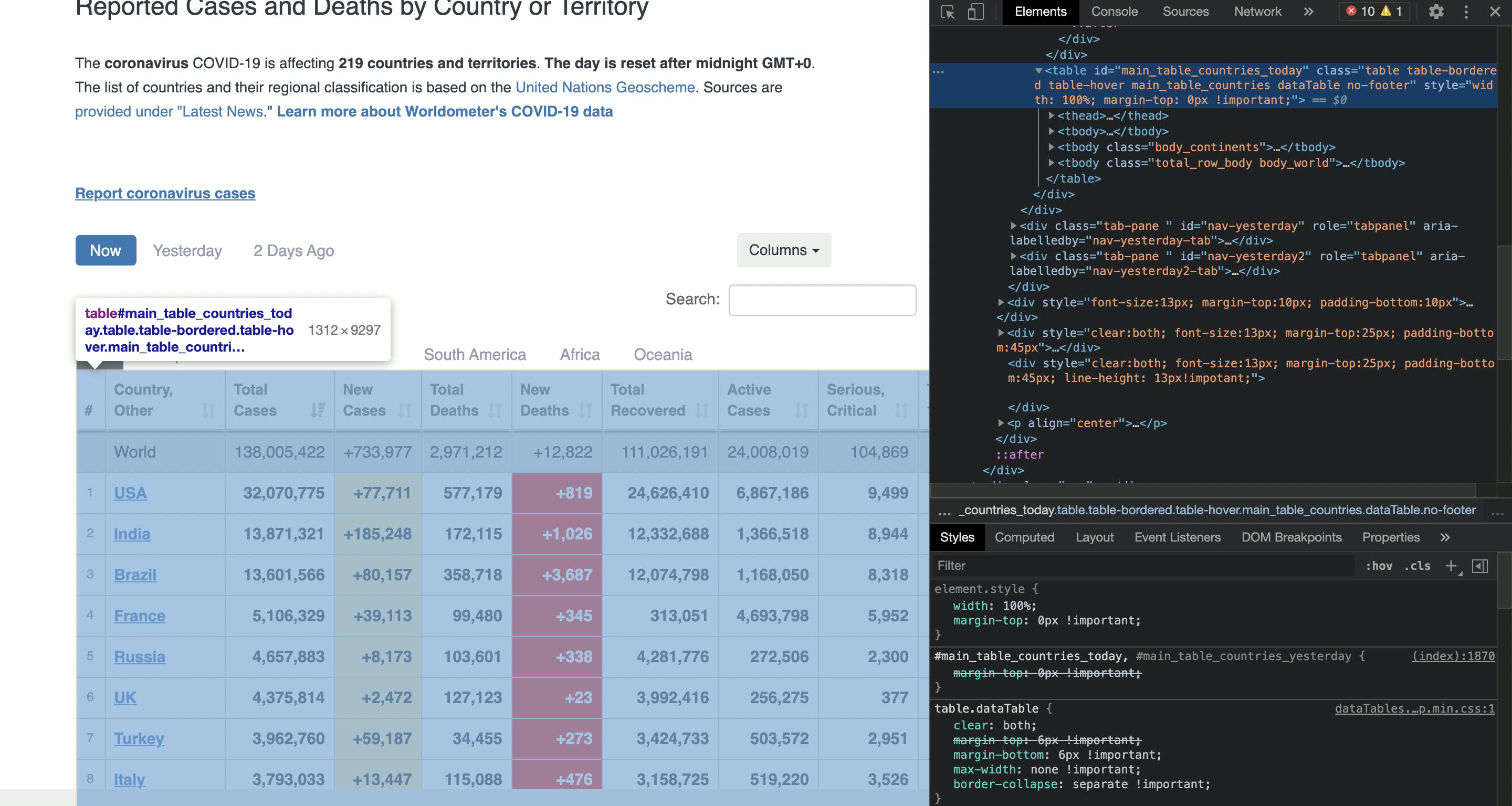
The table has an id "main_table_countries_today". We will use the id to get the table element. Let's talk about the structure of the table
<table>
<thead>
</thead>
<tr>
<td> </td>
<td> </td>
<td> </td>
.
.
.
.
</tr>
</table>

"thead" contains the header row ( "Country,Other" , "Total Cases" , "New Cases" .........) . If this seems confusing, let's start actually scraping the elements and see the output
import requests
from bs4 import BeautifulSoup
html = requests.get("https://www.worldometers.info/coronavirus/").text
soup = BeautifulSoup(html, features= 'html.parser')
table = soup.select("#main_table_countries_today")[0]
headers = table.find("thead").get_text()
print(headers)
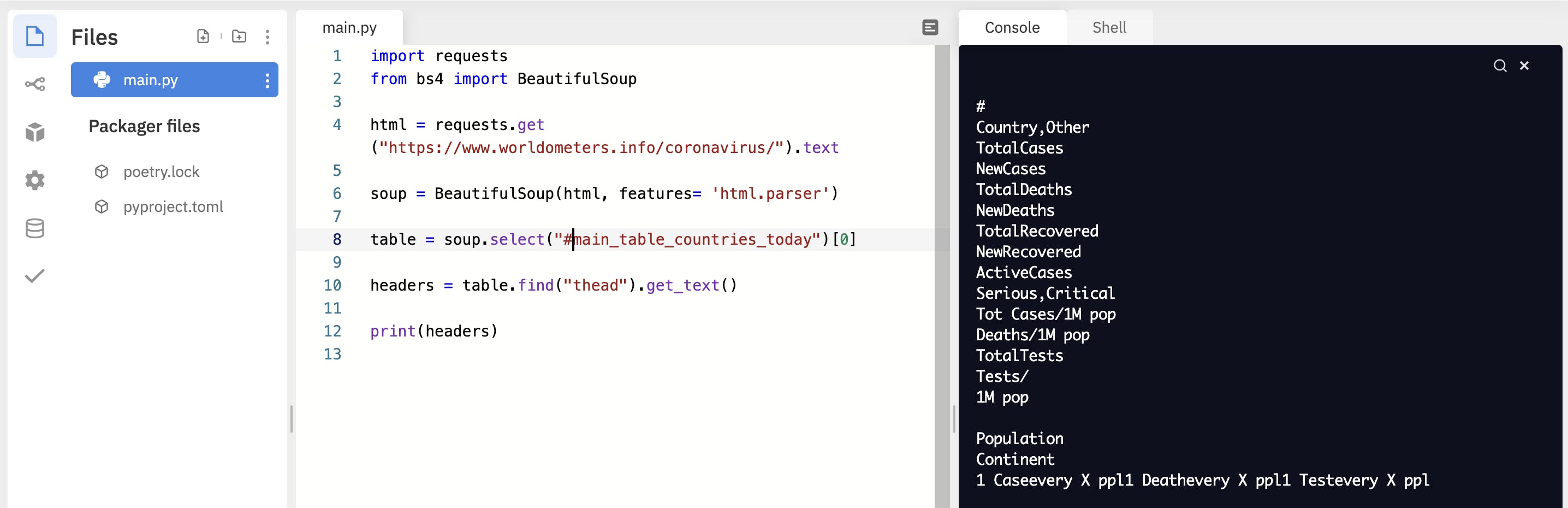
We can use the split() function to break the string into a list of elements.
headers = headers.split("\n")
headers = [header for header in headers if header]
print(headers)
'''
OUTPUT
['#', 'Country,Other', 'TotalCases', 'NewCases', 'TotalDeaths',
'NewDeaths', 'TotalRecovered', 'NewRecovered', 'ActiveCases',
'Serious,Critical', 'Tot\xa0Cases/1M pop', 'Deaths/1M pop', 'TotalTests', 'Tests/',
'1M pop', 'Population', 'Continent',
'1 Caseevery X ppl1 Deathevery X ppl1 Testevery X ppl']
'''
We split by "/n" and then clean up the data. We remove the empty elements. Now let's try to scrap one of the "tr" elements
num_headers = len(headers)
table_body = table.find("tbody")
rows = table_body.find_all("tr")
for idx,row_element in enumerate(rows[8:]):
row= row_element.get_text().split("\n")[1:]
if len(row) != num_headers:
print("Error!")
break
print(" No Errors")
'''
OUTPUT
No Errors
'''
- We get all the
elements - We start from element 8 since the row with "USA" is the 8th element in the list.
- The first element in the row is an empty element and ignore it
- We put a check to ensure that the length of the row and the headers are the same
Now, we have all the data. The data can be transformed and stored as a list of dictionaries or in a CSV.
How to get attributes of the tags
Let's try to get the href value inside a "a tag".
a_tag = soup.find('a')
print(a_tag)
print(f"Attributes : {a_tag.__dict__['attrs']}")
'''
OUTPUT
<a class="navbar-brand" href="/"><img border="0" src="/img/worldometers-logo.gif" title="Worldometer"/></a>
Attributes : {'href': '/', 'class': ['navbar-brand']}
'''
To get the href, we can simply do the following
href = a_tag['href']
Let's try to get the URL of the image inside the "a tag", i.e the value for "src"
img = soup.select("a img")[0]
print(img)
img_src = img['src']
print(f'Src is {img_src}')
'''
OUTPUT
<img border="0" src="/img/worldometers-logo.gif" title="Worldometer"/>
Src is /img/worldometers-logo.gif
'''