


Today, we will be discussing web scraping using Python. We will be using the library Beautiful Soup and Requests to scrape Worldometer's Covid Tracker. Before we get started with scraping the website, let's install the required packages.
Pre-requisites
Some Familiarity with HTML and CSS Selectors
Install Packages
pip install beautifulsoup4, requests
Creating an instance of Beautiful Soup
Beautiful Soup is an HTML parser, i.e if it is given a string with a bunch of HTML code, it can help us extract specific content we need, for example
- tables
- lists
- links
- text inside a particular section etc
How do we get a string with a bunch of HTML code? We use the requests library. If we use the requests library to make a request to a webpage, it will return the HTML content of the webpage as a string
import requests
from bs4 import BeautifulSoup
html = requests.get("https://www.worldometers.info/coronavirus/").text
print(html)
print(type(html))
The output will be the HTML for the home page of Worldometer. The type of the variable 'html' is str.
Now, we will create an instance of BeautifulSoup and pass the HTML string as an argument.
soup = BeautifulSoup(html, features= 'html.parser')
Some Useful Functions
Prettify
print(soup.prettify())
This prints the HTML string in a pretty format with indentations.
First instance of a tag
We will use the find function. Let's try to find the first instance of an 'div' tag on the worldometer page
print(soup.find("div"))
print("-x-x-x-x-x-x-x-")
print(soup.find("div").get_text())
The first print statement will print the first instance of the div tag and all the other HTML elements inside. If we only want the text inside the div block, we can use the get_text() function.
Get all instances of a tag
div_elements = soup.find_all("div")
for element in div_elements:
print(element)
print("-x-x-x-x-x-x-x")
print(element.get_text())
break
This returns an iterable consisting of all the div elements on the page. We can simply loop over the iterable and use the get_text() function to get the text content inside each div. Notice how the output of the above code and code in the previous section are the same. This is because the first element in the iterable is the same div block as the one returned by find().
Specifying CSS class and ID
The find() and find_all() function can take in the following arguements
- class_ = The name of the class
- id = The name of the id
Let's try to get the number of Corona Virus Cases

As you can see, the number is inside a div block with a class name "maincounter-number". The following piece of code would return the number
print( soup.find('div',class_='maincounter-number').get_text() )
We specify that we are looking for a div and pass the class name "maincounter-number" as an argument. Again, we use the get_text() method to get the text content, i.e the number.
Now let's try to get the text inside the navbar using it's id.
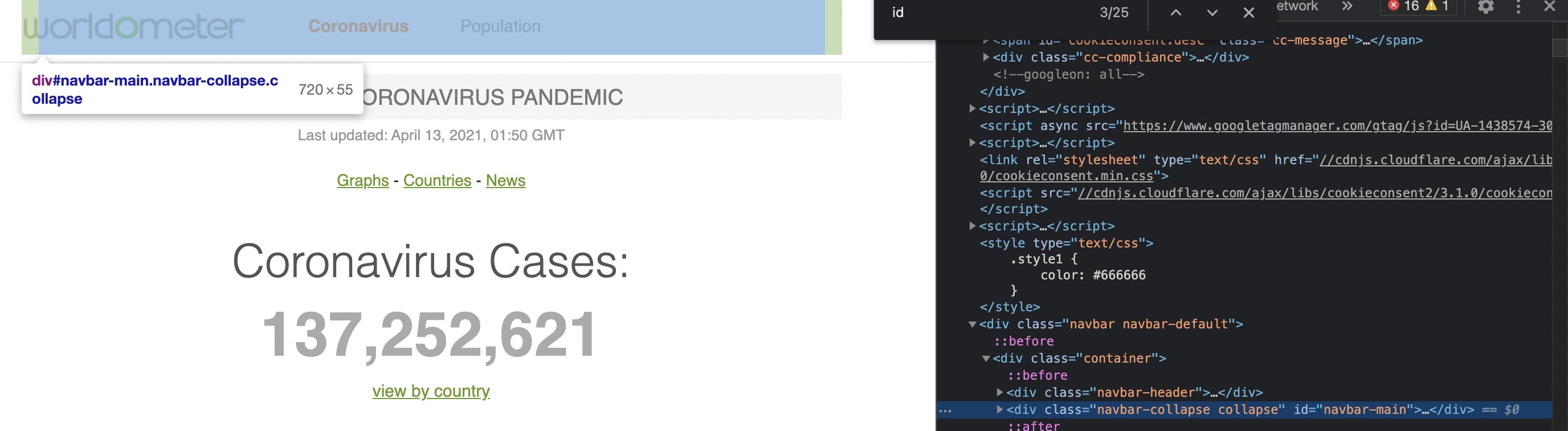
It has id = "navbar-main".
print( soup.find('div',id = "navbar-main").get_text() )
As you can see it's pretty similar to when we were trying to get the number of coronavirus cases. The only difference we are setting the value for id instead of class_.
CSS Selectors
We can combine elements and class names or ids as well. The select() function is similar to the find_all() function. Let's look at some CSS Selectors. Below is the syntaxt
soup.find('css_selectors').get_text()
- h1 - finds all h1 tags
- div p - all the blocks which have a
inside a
- div.maincounter-number - finds all div blocks with a class name "maincounter-number"
- div#navbar-main - finds the div block with id "navbar-main"
- body p a — finds all a tags inside of a p tag inside of a body tag.
Let's try to get the number of coronavirus cases and the text inside the navbar using the select() function.
print( soup.select('div.maincounter-number')[0].get_text())
print( soup.select('div#navbar-main')[0].get_text())
The select() functions returns an iterable, therefore we will either need to iterate over it or use an index to get the text inside the element.
In the next part, we will try to scrape the table and discuss some more usecases using Beautiful Soup